ChatGLM2-6b本地部署教程
一、ChatGLM2-6B介绍
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。 ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答,更多信息请参考我们的博客
ChatGLM2-6B 是开源中英双语对话模型 ChatGLM-6B 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,ChatGLM2-6B 引入了如下新特性:
更强大的性能:基于 ChatGLM 初代模型的开发经验,我们全面升级了 ChatGLM2-6B 的基座模型。ChatGLM2-6B 使用了 GLM 的混合目标函数,经过了 1.4T 中英标识符的预训练与人类偏好对齐训练,评测结果显示,相比于初代模型,ChatGLM2-6B 在 MMLU(+23%)、CEval(+33%)、GSM8K(+571%) 、BBH(+60%)等数据集上的性能取得了大幅度的提升,在同尺寸开源模型中具有较强的竞争力。
更长的上下文:基于 FlashAttention 技术,我们将基座模型的上下文长度(Context Length)由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练,允许更多轮次的对话。但当前版本的 ChatGLM2-6B 对单轮超长文档的理解能力有限,我们会在后续迭代升级中着重进行优化。
更高效的推理:基于 Multi-Query Attention 技术,ChatGLM2-6B 有更高效的推理速度和更低的显存占用:在官方的模型实现下,推理速度相比初代提升了 42%,INT4 量化下,6G 显存支持的对话长度由 1K 提升到了 8K。
更开放的协议:ChatGLM2-6B 权重对学术研究完全开放,在填写问卷进行登记后亦允许免费商业使用。
官方介绍:
二、硬件及软件环境
2.1硬件环境
阿里云的魔搭社区免费环境
| CPU | 8核 |
| 内存 | 32G |
| 显卡 | 无 |
2.2软件环境
| 操作系统 | ubuntu20.04 |
| python版本 | 3.8 |
| pytorch | 2.0.1 |
三、环境搭建
由于是现成的环境,这里我们直接略过
3.1 下载ChatGLM2-6B源码
git clone https://github.com/THUDM/ChatGLM2-6B
如果下载慢可以使用github加速服务
git clone https://ghproxy.com/https://github.com/THUDM/ChatGLM2-6B

3.2 下载模型文件
这一步由于模型文件很大,所以下载很慢要耐心等待
git clone https://huggingface.co/THUDM/chatglm2-6b
机器性能不好可以使用int4
git clone https://huggingface.co/THUDM/chatglm2-6b-int4

3.3 依赖安装
cd ChatGLM2-6b pip install -r requirements.txt
3.4修改并运行模型
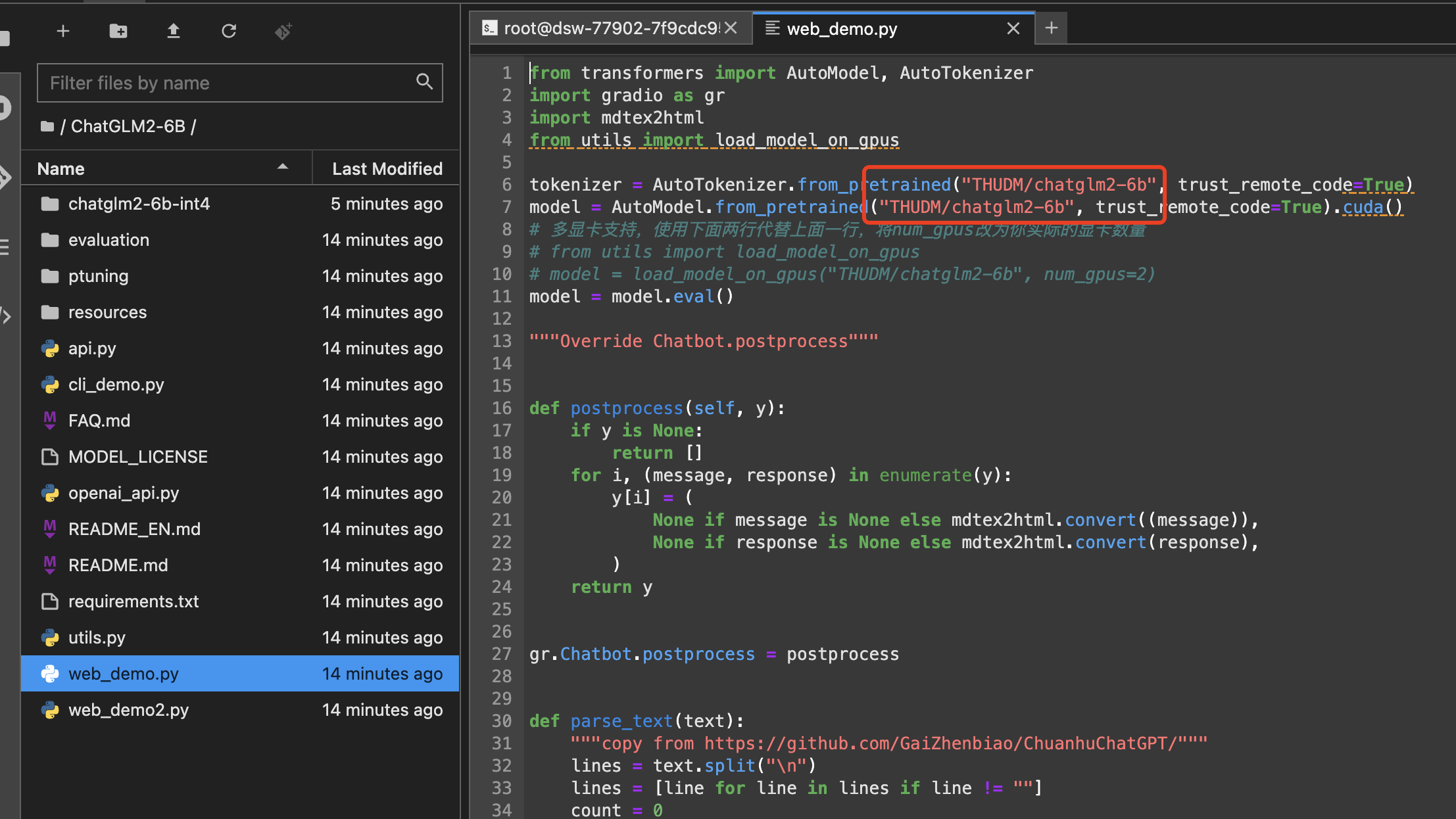
更改红框的路径
tokenizer = AutoTokenizer.from_pretrained("./chatglm2-6b-int4", trust_remote_code=True)
model = AutoModel.from_pretrained("./chatglm2-6b-int4", trust_remote_code=True).float()由于这个服务器没有gpu所以用float()代表用cpu跑
执行
python web_demo.py
不出意外会运行成功

点击上面链接就可以访问对话界面

